AMD Cypress(RV870)拉開了DX11時代的序幕,NVIDIA Fermi(GT300)正在掀起新的浪潮。
今天凌晨,NVIDIA在GPU技術會議上終於揭開了全新架構的秘密,並首次展示了新一代顯
卡。
一、遲來的怪獸
先看這張圖:
http://news.mydrivers.com/Img/20091001/01244894.png
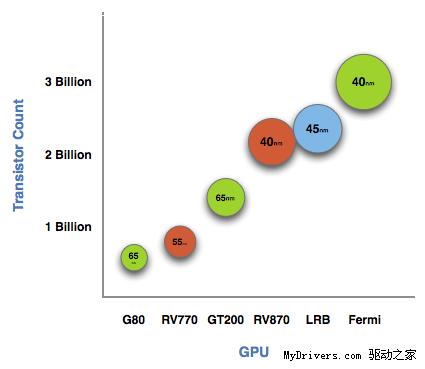
橫向是NVIDIA、AMD歷代圖形核心(以及Intel Larrabee),縱向是晶體管數量,各個圓圈
上標注的則是製造工藝——右上角最龐大、最惹眼的就是今天的主角,NVIDIA Fermi。
GT200的14億個晶體管曾經讓我們驚歎,Cypress的21.5億個相比RV770的9.56億個增加了
一倍多,而Fermi達到了史無前例的30億個,同樣比自己的上一代翻了一番還多,比對手
也多了40%。
從最高層面上說,Fermi很簡單,無非是512個流處理器,384-bit GDDR5顯存,而深層次
的架構我們會在稍後逐一揭曉,不過Fermi至今還停留在紙面上,還不是一款真正的產品
,所以型號劃分、時鐘頻率、售價等等都還沒有確定。事實上,直到兩個月前NVIDIA才第
一次讓人看到了樣品,最近不久剛剛獲得可以正常工作的芯片,正式發佈至少要到今年年
底,而全面上市就是明年第一季度的事兒了。
Fermi為什麼這麼晚?NVIDIA產品營銷副總裁Ujesh Desai說了一句:因為設計這麼大的
GPU實在是太TMD的難了。
http://news.mydrivers.com/Img/20091001/S01250485.jpg
 首次公佈的Fermi核心照
首次公佈的Fermi核心照
二、來自RV770/GT200的教訓
AMD用RV770核心給NVIDIA好好上了一課,龐大而沉重的GT200失去了反擊之力,CUDA、
PhysX這種對手所沒有的功能特性於是成了宣傳重點。
作為GeForce業務負責人,Ujesh Desai願意承擔責任,並承認在GT200時代嚴重失策。根
據RV670 Radeon HD 3800的表現,NVIDIA推測其繼任者的性能也不過爾爾,但RV770的表
現大大出乎意料,而GT200定價過高,最終導致了一夜之間暴降千元的悲劇。
NVIDIAGPU工程副總裁Jonah Alben沒有把責任都推到Ujesh身上,承認自己在工程上也有
失誤。GT300從一開始就應該採用新的55nm工藝,但NVIDIA在130nm NV30 GeForce FX被
150nm Radeon 9700 Pro大敗之後趨於保守,最後一次使用了65nm工藝,最終成就了一個
面積龐大、功耗超高的巨無霸。
雖然40nm工藝進程依然稍微落後,NVIDIA不會在同一條河裡摔倒兩次,沒有在Fermi上沿
用55nm,否則又是一顆無法接受的大芯片。
不過NVIDIA暫時還沒有透露Fermi的具體大小,只能估計一下。Fermi和Cypress都是40nm
工藝,假設核心面積和晶體管數量呈等比例,那麼在後者334平方毫米的基礎上,Fermi將
是466平方毫米,比576平方毫米的GT200小足足兩成。
儘管AMD的Sweet Point策略讓NVIDIA吃盡了苦頭,不過NVIDIA依然認為最重要的並非首先
開發價格較低的小芯片,而是提高大芯片的效率,然後衍生出不同的尺寸和配置規格。期
待Fermi的主流版本能在明年盡快出爐。
http://news.mydrivers.com/img/20080625/S03403062.png
 GT200/RV770/Penryn核心對比
GT200/RV770/Penryn核心對比
三、不再只是遊戲
NVIDIA相信Fermi在3D遊戲裡會比Radeon HD 5870更快,當然不快也不行,但是如果你只
是把Fermi單純地看作是一顆遊戲GPU就錯了,因為它的真正目標是Tesla,是高性能通用
計算,是個人和數據中心超級計算機——這就是GT300里邊那個字母T的含義,它要做一顆
通用目的微處理器。
這有點兒像Intel Nehalem架構,確切目標也不是桌面,而是高性能計算服務器領域,所以
新的Xeon處理器才在服務器工作站上橫掃一片,但遊戲性能並不比Core 2 Quad好多少。
http://news.mydrivers.com/Img/20091001/01332921.jpg
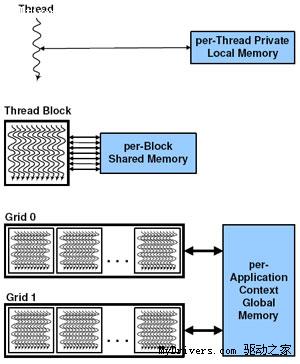
NVIDIA聲稱,要達到同樣的性能,使用CPU就得2000台x86服務器,總成本約800萬美元,
功耗1200kW,而換成GPU只需32台Tesla S1070s系統(如下圖),成本不過40萬美元,功耗
更是僅僅45kW。雖然這裡沒有算上驅動Tesla所需要的服務器(畢竟GPU不可能完全擺脫
CPU),但這部分佔得也不會太多。
http://news.mydrivers.com/Img/20091001/01253037.jpg

NVIDIA預計,未來18個月內各高性能市場總價值如下:地震3億美元、超級計算2億美元、
大學1.5億美元、國防2.5億美元、金融2.3億美元。雖然上個季度Tesla只帶來了1000萬美
元的收入,占NVIDIA總收入的1.3%,但NVIDIA相信它前途無量,所以Fermi架構的很多地
方都是專門為此設計的。
其實藉著DX10統一渲染的東風,NVIDIA從G80就開始了通用計算的努力,GT200更進一步,
但它們主要還是一顆圖形芯片,直到Fermi,不但肩負雙重使命,而且同樣重要。AMD有3A
一體化平台,Intel也在開發獨立顯卡,NVIDIA自然不能坐以待斃,正在朝著視覺計算邁
進。
http://news.mydrivers.com/Img/20091001/01253916.jpg

四、Fermi架構解析
1、SP、SM
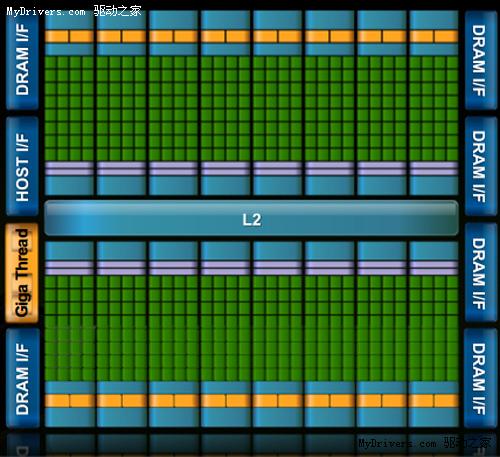
從高層次上看,Fermi和GT200結構形似,並無太大不同,但往身處看會發現絕大部分都已
經進化。
http://news.mydrivers.com/Img/20091001/01263368.jpg
 http://news.mydrivers.com/Img/20091001/01292943.jpg
http://news.mydrivers.com/Img/20091001/01292943.jpg
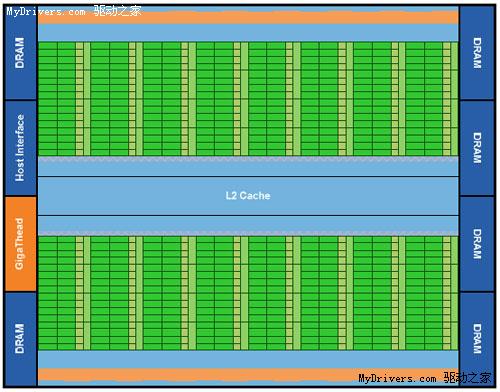
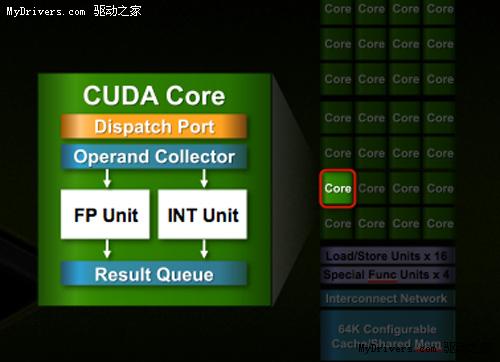
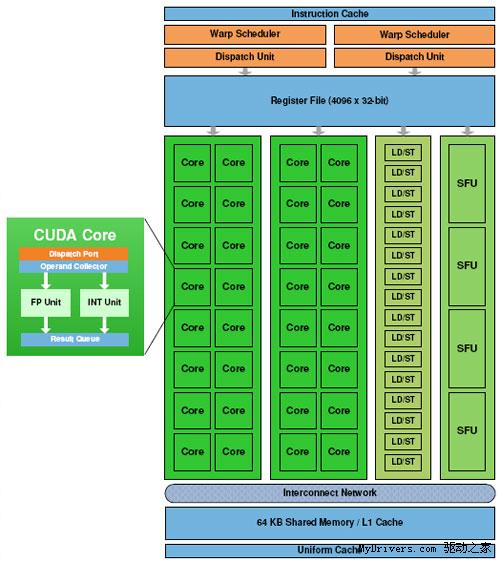
最核心的流處理器(Streaming Processor/SP)現在不但數量大增,還有了個新名字CUDA核
心(CUDA Core),由此即可看出NVIDIA的轉型之意,不過我們暫時還是繼續沿用流處理器
的說法。
所有流處理器現在都符合IEEE 754-2008浮點算法(Cypress也是如此)和完整的32位整數算
法,而後者在過去只是模擬的,事實上僅能計算24-bit整數乘法;同時引入的還有積和熔
加運算(Fused Multiply-Add/FMA),每循環操作數單精度512個、單精度256個。所有一切
都符合業界標準,計算結果不會產生意外偏差。
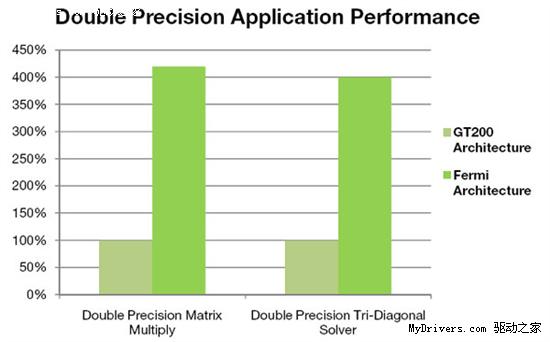
雙精度浮點(FP64)性能大大提升,峰值執行率可以達到單精度浮點(FP32)的1/2,而過去
只有1/8,AMD現在也不過1/5,比如Radeon HD 5870分別為單精度2.72TFlops、雙精度
544GFlops。由於最終核心頻率未定,所以暫時還不清楚Fermi的具體浮點運算能力(雙精
度預計可達624GFlops)。
http://news.mydrivers.com/Img/20091001/01271118.jpg
 http://news.mydrivers.com/Img/20091001/S01302202.jpg
http://news.mydrivers.com/Img/20091001/S01302202.jpg
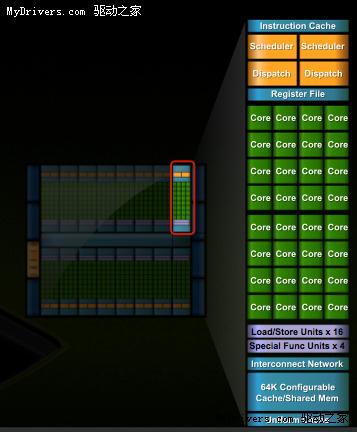
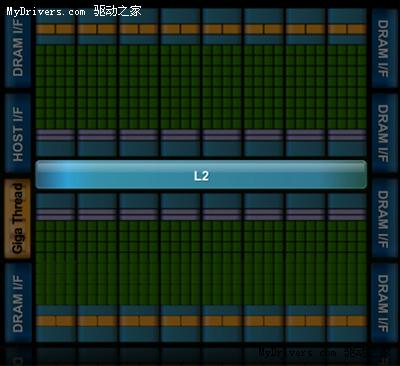
G80/GT200都是8個流處理器構成一組SM(Streaming Multiprocessor),Fermi增加到了32個
,最多16組,少於GT200的30組,但流處理器總量從240個增至512個,是G80的整整四倍。
除了流處理器,每組SM還有4個特殊功能單元(Special Function UnitSFU),用於執行抽
像數學和插值計算,G80/GT200均為2個。同時MUL已被刪掉,所以不會再有單/雙指令執行
計算率了。
至於SM之上的紋理處理器群(Texture Processor Cluster/TPC),NVIDIA暫時沒有披露具
體組成方式,而且ROP單元、紋理/像素填充率等其它圖形指標也未公佈。
http://news.mydrivers.com/Img/20091001/01272121.jpg
 http://news.mydrivers.com/Img/20091001/01291485.jpg
http://news.mydrivers.com/Img/20091001/01291485.jpg
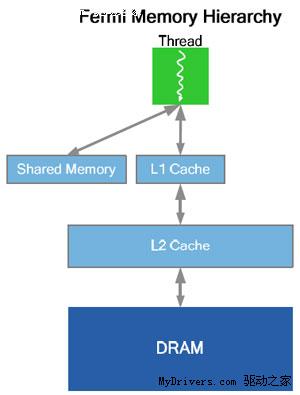
2、緩存
GT200的每組SM都有16KB共享內存,由其中8個SP使用。注意它們不是緩存(cache),而是
軟件管理的內存(memory),可以寫入、讀取數據。為了滿足應用程序和通用計算的需要,
Fermi引入了真正的緩存,每組SM擁有64KB可配置內存(合計1MB),可分成16KB共享內存加
48KB一級緩存,或者48KB共享內存加16KB一級緩存,可靈活滿足不同類型程序的需要。
GT200的每組TPC還有一個一級紋理緩存,不過當GPU出於計算模式的時候就沒什麼用了,
故而Fermi並未在這方面進行增強。
整個芯片擁有一個容量768KB的共享二級緩存,執行原子內存操作(AMO)的時候比GT200快
5-20倍。
http://news.mydrivers.com/Img/20091001/01273069.jpg
 http://news.mydrivers.com/Img/20091001/01321743.jpg
http://news.mydrivers.com/Img/20091001/01321743.jpg
3、效率
CPU和GPU執行的都是被稱作線程的指令流。高端CPU現在每次最多只能執行8個線程
(Intel Core i7),而GPU的並行計算能力就強大多了:G80 12288個、GT200 30720個、
Fermi 24576個。
為什麼Fermi還不如GT200多?因為NVIDIA發現計算的瓶頸在於共享內存大小,而不是線程
數,所以前者從16KB翻兩番達到64KB,後者則減少了20%,不過依然是G80的兩倍,而且
每32個線程構成一組「Warp」。
在G80和GT200上,每個時鐘週期只有一半Warp被送至SM,換言之SM需要兩個循環才能完整
執行32個線程;同時SM分配邏輯和執行硬件緊密聯繫在一起,向SFU發送線程的時候整個
SM都必須等待這些線程執行完畢,嚴重影響整體效率。
Fermi解決了這個問題,在每個SM前端都有兩個Warp調度器和兩個獨立分配單元,並且和
SM其它部分完全獨立,均可在一個時鐘循環裡選擇發送一半Warp,而且這些線程可以來自
不同的Warp。分配單元和執行硬件之間有一個完整的交叉開關(Crossbar),每個單元都可
以像SM內的任何單元分配線程(不過存在一些限制)。
這種線程架構也不是沒有缺點,就是要求Warp的每個線程都必須同時執行同樣的指令,否
則會有部分單元空閒。每組SM每個循環內可以執行的不同操作數:FP32 32個、FP64 16個
、INT 32個、SFU 4個、LD/ST 16個。
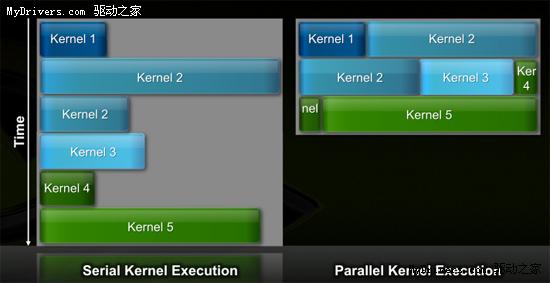
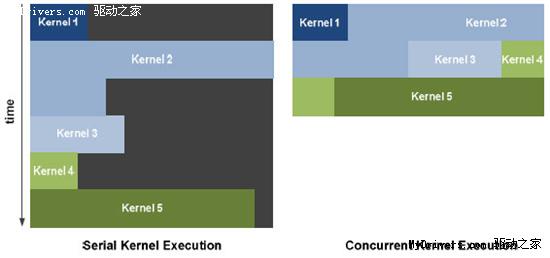
4、並行內核(Parallel Kernel)
在GPU編程術語中,內核是運行在GPU硬件上的一個功能或小程序。G80/GT200整個芯片每
次只能執行一個內核,容易造成SM單元閒置。這在圖形運算中不是問題,通用計算上就不
行了。
Fermi的全局分配邏輯則可以向整個系統發送多個並行內核,不然SP數量翻一番還多,更
容易浪費。
應用程序在GPU和CUDA模式之間的切換時間也快得多了,NVIDIA宣稱是GT200的10倍。外部
連接亦有改進,Fermi現在支持和CPU之間的並行傳輸,而之前都是串行的。
http://news.mydrivers.com/Img/20091001/01281701.jpg
 http://news.mydrivers.com/Img/20091001/S01283201.jpg
http://news.mydrivers.com/Img/20091001/S01283201.jpg
5、ECC支持
AMD Cypress可以檢測內存總線上的錯誤,卻不能修正,而NVIDIA Fermi的寄存器文件、
一級緩存、二級緩存、DRAM全部完整支持ECC錯誤校驗,這同樣是為Tesla準備的,之前我
們也提到過。
很多客戶此前就是因為Tesla沒有ECC才拒絕採納,因為他們的安裝量非常龐大,必須有
ECC。
6、統一64-bit內存尋址
以前的架構裡多種不同載入指令,取決於內存類型:本地(每線程)、共享(每組線程)、全
局(每內核)。這就和指針造成了麻煩,程序員不得不費勁清理。
Fermi統一了尋址空間,簡化為一種指令,內存地址取決於存儲位置:最低位是本地,然
後是共享,剩下的是全局。這種統一尋址空間是支持C++的必需前提。
GT80/GT200的尋址空間都是32-bit的,最多搭配4GB GDDR3顯存,而Fermi一舉支持64-bit
尋址,即使實際尋址只有40-bit,支持顯存容量最多也可達驚人的1TB,目前實際配置最
多6GB GDDR5——仍是Tesla。
7、新的指令集架構(ISA)
下邊對開發人員來說是非常酷的:NVIDIA宣佈了一個名為「Nexus」的插件,可以在
Visual Studio裡執行CUDA代碼的硬件調試,相當於把GPU當成CPU看待,難度大大降低。
Fermi的指令集架構大大擴充,支持DX11和OpenCL義不容辭,C++前邊也已經說過,現在又
多了Visual Studio,當然還有C、Fortran、OpenGL 3.1/3.2。
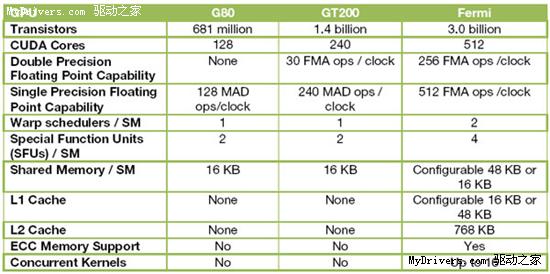
最後匯總一下G80、GT200、Fermi的差異:
http://news.mydrivers.com/Img/20091001/S01395246.jpg
五、Fermi樣卡展示
說了這麼半天的架構技術,我也有點兒不耐煩了,下邊就來點兒更實際的,看看黃仁勳和
Fermi樣卡。
http://news.mydrivers.com/Img/20091001/S01402363.jpg
 http://news.mydrivers.com/Img/20091001/S01402369.jpg
http://news.mydrivers.com/Img/20091001/S01402369.jpg
 http://news.mydrivers.com/Img/20091001/S01402376.jpg
http://news.mydrivers.com/Img/20091001/S01402376.jpg

體積、樣式和我們想像得差不多,不過輸出接口只有一個DVI?別忘了這不是GeForce,而
是Tesla。AMD著力宣傳ATI Eyefinity單卡多顯技術,DVI、HDMI、DisplayPort齊上陣,
而NVIDIA把目光投向了高性能通用計算,雙雄漸行漸遠。
這下知道NVIDIA為什麼說DX11不是唯一了吧?絕非只是冒酸水。
http://news.mydrivers.com/1/145/145916.htm
以現在這時間點來說 要評論什麼還早了點
比如5770雖然可能兩倍於4850的價格 效能可能沒有
而GT300也可能有類似情況之類
現在頂多先知道96GT以下的CP值跟4770賣的比4850貴 還熱門到缺貨之類
不過在漸行漸遠的條件下 要相比價值恐怕又是件更難的事了
例如代工雙雄之爭
--
今天凌晨,NVIDIA在GPU技術會議上終於揭開了全新架構的秘密,並首次展示了新一代顯
卡。
一、遲來的怪獸
先看這張圖:
http://news.mydrivers.com/Img/20091001/01244894.png
橫向是NVIDIA、AMD歷代圖形核心(以及Intel Larrabee),縱向是晶體管數量,各個圓圈
上標注的則是製造工藝——右上角最龐大、最惹眼的就是今天的主角,NVIDIA Fermi。
GT200的14億個晶體管曾經讓我們驚歎,Cypress的21.5億個相比RV770的9.56億個增加了
一倍多,而Fermi達到了史無前例的30億個,同樣比自己的上一代翻了一番還多,比對手
也多了40%。
從最高層面上說,Fermi很簡單,無非是512個流處理器,384-bit GDDR5顯存,而深層次
的架構我們會在稍後逐一揭曉,不過Fermi至今還停留在紙面上,還不是一款真正的產品
,所以型號劃分、時鐘頻率、售價等等都還沒有確定。事實上,直到兩個月前NVIDIA才第
一次讓人看到了樣品,最近不久剛剛獲得可以正常工作的芯片,正式發佈至少要到今年年
底,而全面上市就是明年第一季度的事兒了。
Fermi為什麼這麼晚?NVIDIA產品營銷副總裁Ujesh Desai說了一句:因為設計這麼大的
GPU實在是太TMD的難了。
http://news.mydrivers.com/Img/20091001/S01250485.jpg
二、來自RV770/GT200的教訓
AMD用RV770核心給NVIDIA好好上了一課,龐大而沉重的GT200失去了反擊之力,CUDA、
PhysX這種對手所沒有的功能特性於是成了宣傳重點。
作為GeForce業務負責人,Ujesh Desai願意承擔責任,並承認在GT200時代嚴重失策。根
據RV670 Radeon HD 3800的表現,NVIDIA推測其繼任者的性能也不過爾爾,但RV770的表
現大大出乎意料,而GT200定價過高,最終導致了一夜之間暴降千元的悲劇。
NVIDIAGPU工程副總裁Jonah Alben沒有把責任都推到Ujesh身上,承認自己在工程上也有
失誤。GT300從一開始就應該採用新的55nm工藝,但NVIDIA在130nm NV30 GeForce FX被
150nm Radeon 9700 Pro大敗之後趨於保守,最後一次使用了65nm工藝,最終成就了一個
面積龐大、功耗超高的巨無霸。
雖然40nm工藝進程依然稍微落後,NVIDIA不會在同一條河裡摔倒兩次,沒有在Fermi上沿
用55nm,否則又是一顆無法接受的大芯片。
不過NVIDIA暫時還沒有透露Fermi的具體大小,只能估計一下。Fermi和Cypress都是40nm
工藝,假設核心面積和晶體管數量呈等比例,那麼在後者334平方毫米的基礎上,Fermi將
是466平方毫米,比576平方毫米的GT200小足足兩成。
儘管AMD的Sweet Point策略讓NVIDIA吃盡了苦頭,不過NVIDIA依然認為最重要的並非首先
開發價格較低的小芯片,而是提高大芯片的效率,然後衍生出不同的尺寸和配置規格。期
待Fermi的主流版本能在明年盡快出爐。
http://news.mydrivers.com/img/20080625/S03403062.png
三、不再只是遊戲
NVIDIA相信Fermi在3D遊戲裡會比Radeon HD 5870更快,當然不快也不行,但是如果你只
是把Fermi單純地看作是一顆遊戲GPU就錯了,因為它的真正目標是Tesla,是高性能通用
計算,是個人和數據中心超級計算機——這就是GT300里邊那個字母T的含義,它要做一顆
通用目的微處理器。
這有點兒像Intel Nehalem架構,確切目標也不是桌面,而是高性能計算服務器領域,所以
新的Xeon處理器才在服務器工作站上橫掃一片,但遊戲性能並不比Core 2 Quad好多少。
http://news.mydrivers.com/Img/20091001/01332921.jpg
NVIDIA聲稱,要達到同樣的性能,使用CPU就得2000台x86服務器,總成本約800萬美元,
功耗1200kW,而換成GPU只需32台Tesla S1070s系統(如下圖),成本不過40萬美元,功耗
更是僅僅45kW。雖然這裡沒有算上驅動Tesla所需要的服務器(畢竟GPU不可能完全擺脫
CPU),但這部分佔得也不會太多。
http://news.mydrivers.com/Img/20091001/01253037.jpg
NVIDIA預計,未來18個月內各高性能市場總價值如下:地震3億美元、超級計算2億美元、
大學1.5億美元、國防2.5億美元、金融2.3億美元。雖然上個季度Tesla只帶來了1000萬美
元的收入,占NVIDIA總收入的1.3%,但NVIDIA相信它前途無量,所以Fermi架構的很多地
方都是專門為此設計的。
其實藉著DX10統一渲染的東風,NVIDIA從G80就開始了通用計算的努力,GT200更進一步,
但它們主要還是一顆圖形芯片,直到Fermi,不但肩負雙重使命,而且同樣重要。AMD有3A
一體化平台,Intel也在開發獨立顯卡,NVIDIA自然不能坐以待斃,正在朝著視覺計算邁
進。
http://news.mydrivers.com/Img/20091001/01253916.jpg
四、Fermi架構解析
1、SP、SM
從高層次上看,Fermi和GT200結構形似,並無太大不同,但往身處看會發現絕大部分都已
經進化。
http://news.mydrivers.com/Img/20091001/01263368.jpg
最核心的流處理器(Streaming Processor/SP)現在不但數量大增,還有了個新名字CUDA核
心(CUDA Core),由此即可看出NVIDIA的轉型之意,不過我們暫時還是繼續沿用流處理器
的說法。
所有流處理器現在都符合IEEE 754-2008浮點算法(Cypress也是如此)和完整的32位整數算
法,而後者在過去只是模擬的,事實上僅能計算24-bit整數乘法;同時引入的還有積和熔
加運算(Fused Multiply-Add/FMA),每循環操作數單精度512個、單精度256個。所有一切
都符合業界標準,計算結果不會產生意外偏差。
雙精度浮點(FP64)性能大大提升,峰值執行率可以達到單精度浮點(FP32)的1/2,而過去
只有1/8,AMD現在也不過1/5,比如Radeon HD 5870分別為單精度2.72TFlops、雙精度
544GFlops。由於最終核心頻率未定,所以暫時還不清楚Fermi的具體浮點運算能力(雙精
度預計可達624GFlops)。
http://news.mydrivers.com/Img/20091001/01271118.jpg
G80/GT200都是8個流處理器構成一組SM(Streaming Multiprocessor),Fermi增加到了32個
,最多16組,少於GT200的30組,但流處理器總量從240個增至512個,是G80的整整四倍。
除了流處理器,每組SM還有4個特殊功能單元(Special Function UnitSFU),用於執行抽
像數學和插值計算,G80/GT200均為2個。同時MUL已被刪掉,所以不會再有單/雙指令執行
計算率了。
至於SM之上的紋理處理器群(Texture Processor Cluster/TPC),NVIDIA暫時沒有披露具
體組成方式,而且ROP單元、紋理/像素填充率等其它圖形指標也未公佈。
http://news.mydrivers.com/Img/20091001/01272121.jpg
2、緩存
GT200的每組SM都有16KB共享內存,由其中8個SP使用。注意它們不是緩存(cache),而是
軟件管理的內存(memory),可以寫入、讀取數據。為了滿足應用程序和通用計算的需要,
Fermi引入了真正的緩存,每組SM擁有64KB可配置內存(合計1MB),可分成16KB共享內存加
48KB一級緩存,或者48KB共享內存加16KB一級緩存,可靈活滿足不同類型程序的需要。
GT200的每組TPC還有一個一級紋理緩存,不過當GPU出於計算模式的時候就沒什麼用了,
故而Fermi並未在這方面進行增強。
整個芯片擁有一個容量768KB的共享二級緩存,執行原子內存操作(AMO)的時候比GT200快
5-20倍。
http://news.mydrivers.com/Img/20091001/01273069.jpg
3、效率
CPU和GPU執行的都是被稱作線程的指令流。高端CPU現在每次最多只能執行8個線程
(Intel Core i7),而GPU的並行計算能力就強大多了:G80 12288個、GT200 30720個、
Fermi 24576個。
為什麼Fermi還不如GT200多?因為NVIDIA發現計算的瓶頸在於共享內存大小,而不是線程
數,所以前者從16KB翻兩番達到64KB,後者則減少了20%,不過依然是G80的兩倍,而且
每32個線程構成一組「Warp」。
在G80和GT200上,每個時鐘週期只有一半Warp被送至SM,換言之SM需要兩個循環才能完整
執行32個線程;同時SM分配邏輯和執行硬件緊密聯繫在一起,向SFU發送線程的時候整個
SM都必須等待這些線程執行完畢,嚴重影響整體效率。
Fermi解決了這個問題,在每個SM前端都有兩個Warp調度器和兩個獨立分配單元,並且和
SM其它部分完全獨立,均可在一個時鐘循環裡選擇發送一半Warp,而且這些線程可以來自
不同的Warp。分配單元和執行硬件之間有一個完整的交叉開關(Crossbar),每個單元都可
以像SM內的任何單元分配線程(不過存在一些限制)。
這種線程架構也不是沒有缺點,就是要求Warp的每個線程都必須同時執行同樣的指令,否
則會有部分單元空閒。每組SM每個循環內可以執行的不同操作數:FP32 32個、FP64 16個
、INT 32個、SFU 4個、LD/ST 16個。
4、並行內核(Parallel Kernel)
在GPU編程術語中,內核是運行在GPU硬件上的一個功能或小程序。G80/GT200整個芯片每
次只能執行一個內核,容易造成SM單元閒置。這在圖形運算中不是問題,通用計算上就不
行了。
Fermi的全局分配邏輯則可以向整個系統發送多個並行內核,不然SP數量翻一番還多,更
容易浪費。
應用程序在GPU和CUDA模式之間的切換時間也快得多了,NVIDIA宣稱是GT200的10倍。外部
連接亦有改進,Fermi現在支持和CPU之間的並行傳輸,而之前都是串行的。
http://news.mydrivers.com/Img/20091001/01281701.jpg
5、ECC支持
AMD Cypress可以檢測內存總線上的錯誤,卻不能修正,而NVIDIA Fermi的寄存器文件、
一級緩存、二級緩存、DRAM全部完整支持ECC錯誤校驗,這同樣是為Tesla準備的,之前我
們也提到過。
很多客戶此前就是因為Tesla沒有ECC才拒絕採納,因為他們的安裝量非常龐大,必須有
ECC。
6、統一64-bit內存尋址
以前的架構裡多種不同載入指令,取決於內存類型:本地(每線程)、共享(每組線程)、全
局(每內核)。這就和指針造成了麻煩,程序員不得不費勁清理。
Fermi統一了尋址空間,簡化為一種指令,內存地址取決於存儲位置:最低位是本地,然
後是共享,剩下的是全局。這種統一尋址空間是支持C++的必需前提。
GT80/GT200的尋址空間都是32-bit的,最多搭配4GB GDDR3顯存,而Fermi一舉支持64-bit
尋址,即使實際尋址只有40-bit,支持顯存容量最多也可達驚人的1TB,目前實際配置最
多6GB GDDR5——仍是Tesla。
7、新的指令集架構(ISA)
下邊對開發人員來說是非常酷的:NVIDIA宣佈了一個名為「Nexus」的插件,可以在
Visual Studio裡執行CUDA代碼的硬件調試,相當於把GPU當成CPU看待,難度大大降低。
Fermi的指令集架構大大擴充,支持DX11和OpenCL義不容辭,C++前邊也已經說過,現在又
多了Visual Studio,當然還有C、Fortran、OpenGL 3.1/3.2。
最後匯總一下G80、GT200、Fermi的差異:
http://news.mydrivers.com/Img/20091001/S01395246.jpg
五、Fermi樣卡展示
說了這麼半天的架構技術,我也有點兒不耐煩了,下邊就來點兒更實際的,看看黃仁勳和
Fermi樣卡。
http://news.mydrivers.com/Img/20091001/S01402363.jpg
體積、樣式和我們想像得差不多,不過輸出接口只有一個DVI?別忘了這不是GeForce,而
是Tesla。AMD著力宣傳ATI Eyefinity單卡多顯技術,DVI、HDMI、DisplayPort齊上陣,
而NVIDIA把目光投向了高性能通用計算,雙雄漸行漸遠。
這下知道NVIDIA為什麼說DX11不是唯一了吧?絕非只是冒酸水。
http://news.mydrivers.com/1/145/145916.htm
以現在這時間點來說 要評論什麼還早了點
比如5770雖然可能兩倍於4850的價格 效能可能沒有
而GT300也可能有類似情況之類
現在頂多先知道96GT以下的CP值跟4770賣的比4850貴 還熱門到缺貨之類
不過在漸行漸遠的條件下 要相比價值恐怕又是件更難的事了
例如代工雙雄之爭
--
All Comments